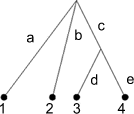
If T is a rooted tree, there is a distinguished vertex of T called the root
and labeled by the letter r. The tree T should be drawn with the root
r at the top of the figure and the edges of the tree below the root.
Each edge in the tree is labeled with a lowercase letter a,b,c, ...
The edges are labeled in alphabetical order starting at the upper left hand
corner, proceeding left to right and top to bottom. The leaves are labeled
with the numbers 1,2,3, ... starting with the left-most leaf and
proceeding left to right.
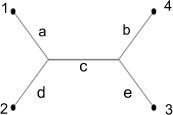
If T is an unrooted tree, it should be drawn with the leaves on a circle.
The edges of T are labeled with lower-case letters a,b,c, ... in
alphabetical order starting at the upper left hand corner of the figure and
proceeding left to right and top to bottom.
The leaves are labeled with the numbers 1,2,3,... starting at the
first leaf "left of 12 o'clock" and proceeding counterclockwise around
the perimeter of the tree.